As the curator of z-table.com, a platform dedicated to the beauty of statistics and mathematics (yeah I know you might object but I find numbers beautiful), I've always been fascinated by the interplay between numbers and narratives. Recently, I've been contemplating launching a YouTube channel to bring mathematical concepts to life through storytelling. In this quest, I've explored various visualization tools and stumbled upon CapCut, an online video and photo editing solution with intriguing features for narrative transformation. While I haven't used CapCut personally, my research into its capabilities has revealed its potential in adapting literary classics to visual media, something that could be invaluable in visualizing mathematical stories. The exploration of CapCut emerged from a desire to break down the complex world of mathematics into engaging, digestible visuals that can capture the imagination of viewers. The platform promises a blend of technological innovation and artistic creativity, potentially bridging the gap between the abstract nature of mathematics and the concrete realm of visual storytelling. This journey isn't just about finding the right tool; it's about reshaping the way we perceive and engage with mathematical concepts. By weaving numbers into visual narratives, we can unlock a new dimension of understanding and appreciation, making mathematics not just a subject to be learned, but a story to be experienced.
The Intersection of Technology and Storytelling: CapCut's Core Tools
At the forefront of CapCut are two groundbreaking features: the video to text converter and the Image Upscaler. These tools transform written content into engaging visual sequences, a process that resonates with my mission to visually interpret mathematical theories and stories.
Deep Dive into CapCut's Video-to-Text Converter
The Video-to-Text converter goes beyond basic transcription. It interprets the essence and mood of the source material, turning it into a visual narrative. This aligns with my vision for the YouTube channel, where complex mathematical concepts could be translated into engaging visual stories, making them accessible and relatable.
Enhancing Visuals with the Image Upscaler
CapCut's image upscaler adjusts images to fit the narrative's context and mood. This feature could be instrumental in emphasizing specific aspects of mathematical stories or theories, enhancing the visual impact and understanding for viewers.

Balancing Text and Visuals: A Crucial Aspect for Mathematical Narratives
Adapting textual content to visual formats is particularly challenging when dealing with abstract concepts like mathematics. CapCut's tools seem capable of addressing this by creating visuals that are not only faithful to the original concept but also enrich the storytelling experience.
Fostering Creative Freedom in Mathematical Storytelling
The flexibility offered by CapCut is inspiring. It suggests possibilities for diverse storytelling approaches, from direct interpretations to more abstract, artistic renditions of mathematical narratives.
Exploring the Evolution of Adaptation in Educational Content
In my journey to find the right tools for the YouTube channel, CapCut's approach to adaptation stood out. Its integration of text-to-video conversion with image scaling offers a comprehensive toolkit for creating educational and engaging content.
Broadening the Scope of Mathematical Visualization
CapCut's features could potentially allow creators to delve into various genres, making intricate mathematical concepts visually interpretable and engaging. This could revolutionize the way mathematics is presented and understood by a broader audience.
CapCut's Potential in Educational Content Creation
The educational implications of CapCut's features are vast. They could be used to create compelling visual representations of mathematical theories and histories, making them more relatable and comprehensible, especially for visual learners.
The Future of Storytelling in Mathematics Education
Looking ahead, the impact of tools like CapCut on storytelling, particularly in educational contexts like mathematics, could be profound. They offer new ways to merge technology and creativity, enriching the learning experience.
The Road Ahead for z-table.com and Beyond
In conclusion, my exploration of CapCut, while still in the research phase, has opened up new avenues for considering how we can adapt complex narratives, like those in mathematics, into visually engaging formats. While CapCut primarily focuses on literary classics, its principles and tools offer valuable insights for my endeavors in visualizing mathematical concepts. As I continue to explore and plan for the upcoming YouTube channel, CapCut stands as an example of the innovative tools available to transform the way we understand and appreciate the intricate world of mathematics and storytelling. The potential of tools like CapCut extends beyond mere content creation; they represent a paradigm shift in educational methodologies. By integrating these tools into z-table.com's content strategy, we can revolutionize the way mathematical stories are told and understood. The future of mathematics education lies in the ability to merge technology with narrative, transforming abstract concepts into captivating visual stories that resonate with a diverse audience. Our journey with CapCut marks the beginning of an exciting chapter in visual storytelling, one where mathematics becomes not just a subject to study, but a universe to explore and marvel at through the lens of innovative technology and creative expression.

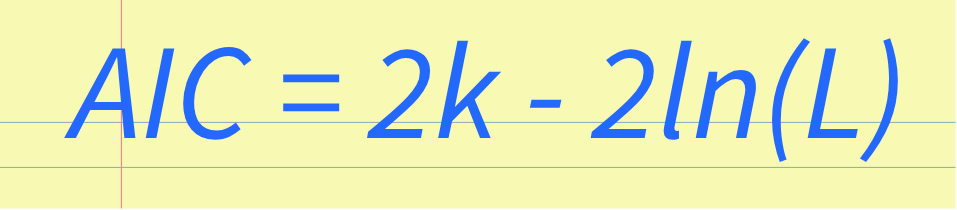
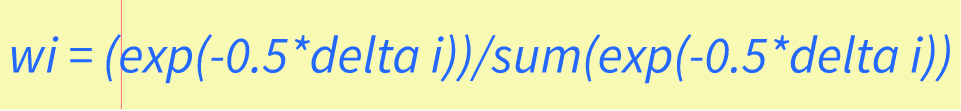
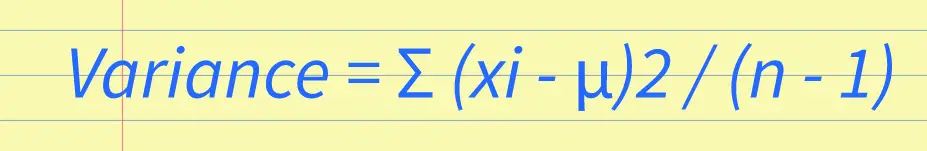



 RSS Feed
RSS Feed